
Notfallwiederherstellung im Rechenzentrum:
Naturkatastrophen sind eine Tatsache des Lebens. Sie kommen jedes Jahr mit wenig Vorwarnung und strahlen eine unglaubliche rohe Kraft aus; alles zerstören, was ihnen in den Weg kommt. Diese "Taten Gottes" spielen weder Favoriten noch kümmern sie sich darum, was sie in ihrem Gefolge zerstören könnten. Sie sind unvorhersehbar, unzuverlässig und unveränderlich.
Genau wie Sie entscheide ich mich für einen Wohnort und ein Unternehmen für einen Standort Rechenzentrum mit etwas Nachdruck auf die Chancen einer Naturkatastrophe. Und genau wie Sie und ich, müssen diese Unternehmen möglicherweise einen Ort bauen oder verlegen, an dem die Wahrscheinlichkeit einer Katastrophe höher ist.
Inevitably data centers will be built in locations that seasonally face the wrath of mother nature and because of this disaster recovery plans (DRP) – sometimes referred to as a business continuity plans (BCP) or business process contingency plans (BPCP) – have to be put in place, in order for organizations to have a plan describing how to deal with potential disasters.
Just as a disaster is an event that makes the continuation of normal functions impossible, a disaster recovery plan consists of the precautions taken so that the effects of a disaster will be minimized and the organization will be able to either maintain or quickly resume mission-critical functions. Typically, Disaster Recovery-Planung beinhaltet eine Analyse der Geschäftsprozesse und des Kontinuitätsbedarfs; es kann auch einen erheblichen Schwerpunkt auf den Katastrophenschutz legen Rechenzentrumsmigration.
Gemäß den Industriestandards gibt es drei Ansätze, um mit Katastrophen umzugehen, wenn sie eintreten:
- HOT Disaster Recovery-Sites:
Diese Sites eignen sich für Anwendungen und Dienste, die von Natur aus sehr kritisch sind und keine Ausfallzeiten während einer Katastrophe riskieren können. Dieser Ansatz ist für geschäftskritische Dienste wie Bank-Rechenzentren, Online-Transaktionsstandorte oder Lager / Share-Rechenzentren erforderlich. Hot-DR-Standorte müssen über eine Online-Sicherung aller Dienste am Notfallwiederherstellungsstandort verfügen. Im Katastrophenfall wird die DR-Site Verbindungen herstellen und das Geschäft wird in kürzester Zeit wieder in Betrieb genommen. Dieser Ansatz ist jedoch äußerst kostspielig und erfordert große Investitionen, da das Rechenzentrum am Standort des DR-Rechenzentrums gespiegelt wird. - COLD DR Sites:
Cold DR-Standorte verfügen über Offsite-Backups auf den wichtigsten Rechenzentrums-Servern und -Diensten. Im Notfall wird das Backup auf neu erworbenen und installierten Servern wiederhergestellt. Die Verzögerungszeit für die Wiederherstellung des Dienstes für diese Sites ist lang und kann im Allgemeinen erst nach einer Woche oder länger wieder aktiv werden. Die Planung an diesen Standorten ist minimal und erfordert lediglich die Identifizierung eines Raums für den DR-Umzug und den Aufbau einer Basisinfrastruktur. -
WARM Disaster Recovery Sites:
Warme DR-Standorte sind eine Mischung aus heißen und kalten DR-Lösungen. Aufgrund von Kostenbeschränkungen oder Anwendungsabhängigkeiten werden nur einige Anwendungen für die Notfallwiederherstellung in Betracht gezogen. RTO variiert bis zu einigen Tagen. Services werden nach Priorität oder Schweregrad wiederhergestellt. Um die Kosten zu kontrollieren, werden nur geschäftskritische Anwendungen für Hot-DR berücksichtigt, und andere werden entweder an einen DR-Standort verschoben oder im Notfall neu erstellt.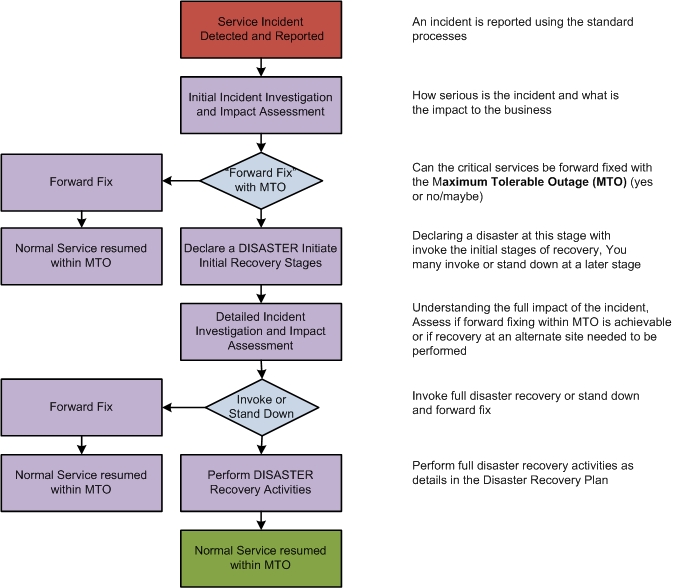
Der Ansatz basiert auf dem Maximum Tolerable Outage (MTO). MTO ist die Zeit, für die ein Unternehmen einen Ausfall tolerieren kann. Jeder Vorfall, der sich für weniger als diesen Zeitraum ereignet, kann nicht als Katastrophe betrachtet werden. Wenn der Vorfall jedoch das MTO überschreitet, ruft das Rechenzentrumsmanagement den DR-Plan auf, wodurch die Auswirkungen auf das Unternehmen theoretisch gemindert werden.
Wenn Sie eine Rechenzentrumsmigration durchführen, finden Sie hier einen hilfreichen Artikel zu Migrationsschritte für Rechenzentren.








